



Those who have been keeping up with the latest advancements in generative artificial intelligence have likely noticed the use of a variety of benchmarks to illustrate language models' capabilities. They assess knowledge, reasoning, comprehension of reading, and coding. Is this information useful for applying Czech law practically, though? We have made the decision to evaluate the language models in the Czech context, and the results are intriguing!
Although there are specialised legal benchmarks such as LawBench or LegalBench, no benchmark or language model is solely focused on Czech and Czech law. As a result, rather than being grounded in concrete facts, the discussions surrounding the application of AI in the Czech Republic are based on haphazard observations.
At HAVEL & PARTNERS, we have long been involved in the legal and technical aspects of automation and artificial intelligence. That is why we want to know what system to use for our legal practice. Since most of us are lawyers, we frequently remember the difficulties in passing the bar exam. This inspired us to prepare language models for mock bar exams and assess their performance.
Artificial intelligence is taking the exam
To evaluate the language models, we used a set of 1,840 bar exam questions from the Czech Bar Association. These questions cover commercial, civil, criminal, constitutional, administrative law, and legal practice legislation. Bar exam takers receive 100 randomised questions and must choose the correct answer from three options. Passing requires accurately answering at least 85 questions.
We followed a similar procedure. We conducted five rounds of testing, with each round containing a set of 100 questions. Thus, each system faced a total of 500 identical questions.
Common system prompt for language models (original is in Czech) |
“You are a legal expert who answers legal questions under Czech law as part of the bar exam. Based on the question and the three options (marked A, B and C), your task is to use your best knowledge and skills to choose the correct answer. No points will be deducted for a wrong answer. Always choose one of the options. Do not explain your choice – simply write the single letter A, B, or C, without any additional text, or your answer will be marked incorrect.” |
Virtual aspiring attorneys introduce themselves
In addition to using well-known generalist AI applications such as Microsoft Copilot and ChatGPT, HAVEL & PARTNERS have also been involved in the development of the WAIR. This application combines language model agents (mostly GPT-4) and retrieval augmented generation (smart addition of relevant sources) to generate legal searches. To compare the language models, we used a WAIR version available to the professional public and not the version used by HAVEL & PARTNERS containing a number of additional internal resources. The following models participated in the testing using their API access:
Model or application name | Example of an application using the model |
Claude-3-Opus | Claude.ai (Anthropic) |
Claude-3-Sonnet | Claude.ai (Anthropic) |
Gemini-1.0-Pro | Gemini (Google) |
GPT-4-Turbo | ChatGPT+ (OpenAI), Copilot (Microsoft) |
GPT-3.5-Turbo | ChatGPT (OpenaAI), Copilot (Microsoft) |
Mistral-Large | Le Chat (Mistral) |
Mixtral-8x7B | Le Chat (Mistral) |
WAIR | WAIR (www.wair.cz) |
How did it turn out?
The test results clearly demonstrate that combining a proficient language model (GPT-4) with intelligent integration of resources is effective. Our WAIR application not only substantially outperformed all language models, but also surpassed the 85% threshold mandated by the Czech Bar Association in all five testing rounds. In contrast, none of the evaluated language models achieved success in any trial.
The recently introduced Claude-3-Opus was the top-performing language model, closely followed by GPT-4-Turbo. A group of models including Gemini-1.0-Pro, Claude-3-Sonnet, and Mistral-Large came next in the rankings. GPT-3.5-Turbo and Mixtral-8x7B ranked lowest, with relatively poor results.
The language models and WAIR application achieved the following success rates after each test:
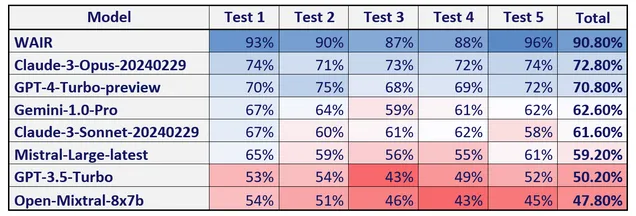
Although the general language models Claude-3-Opus and GPT-4-Turbo did not reach the pass mark, they achieved quite good results given their limited knowledge of specialist legal sources. This demonstrates their excellent text comprehension and reasoning abilities, which could prove useful in legal applications like WAIR or lawyers' daily work despite not having specialised legal training.
Other useful insights for practice
Our testing has revealed additional noteworthy insights to consider when employing AI in the legal field. These findings include:
- GPT-3.5-Turbo, used in the free version of ChatGPT, is clearly already obsolete. It barely exceeded a 50% success rate in the tests and can hardly be recommended for knowledge work in law.
- Claude-3-Opus emerged to be currently the best language model, narrowly outperforming even the previous king, GPT-4-Turbo.
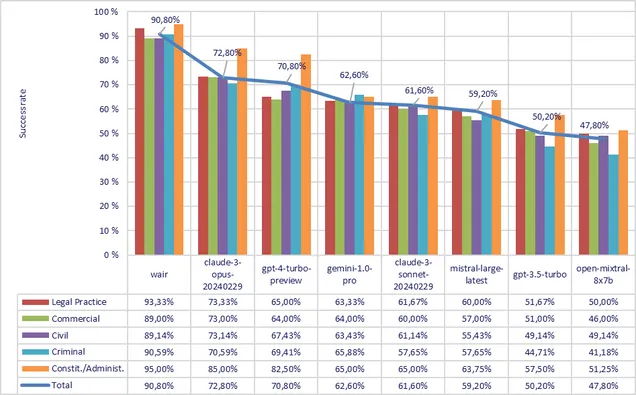
- The majority of systems tested performed significantly better in constitutional and administrative law than other areas. This can be attributed to either less difficult questions or more training data from those legal domains.
- Although the overall ranking of the systems is obvious, some interesting differences emerged when examining success rates in specific legal domains. Specifically, GPT-4-Turbo struggled with legal practice regulations and commercial law, nearly tying the otherwise far weaker Gemini-1.0-Pro. However, GPT-4-Turbo excelled in public law, affirming its leading performance.
- The above shortcomings of GPT-4-Turbo relating to bar rules and commercial law can be easily remedied by supplementing it with suitable materials, as evidenced by the successful outcomes of the WAIR program.
- The field of criminal law is generally the most challenging for language models to grasp. However, Gemini-1.0-Pro stands out as an exception, demonstrating strong capabilities within this complex legal domain.
Overall success rate of language models and WAIR by branches of law
Conclusion
The testing showed the level of ability of the language models and WAIR app to comprehend the legal issue and select the right option using their own knowledge. It should be noted, however, that the evaluation of language models and legal skills as such is considerably more complex.. For instance, our assessments did not examine written argumentation skills, utilising resources, persuasiveness, speed or cost.
Regardless, the test findings have shown us that we should keep evaluating AI and creating our own solutions.
Note
The results presented above should not be interpreted as a conclusive evaluation of the quality or performance of the individual systems tested. Rather, they provide a general overview of the systems' abilities within the narrow scope of responding to test questions related to law. While every effort has been made to ensure the accuracy and objectivity of the information in our testing, we are not liable for any inaccuracies or errors in the comparative data. We always recommend conducting your own analysis and evaluation before selecting the most appropriate solution for your specific legal needs.



